[TIL]SQL ORDER BY| GROUP BY |DESC, ASC | HAVING | COUNT
ORDER BY 순서 정렬

price 로 내림차순 정렬후 같은 값이 있으면 name 오름차순으로 정렬.


price =1, name = 2
위의 예제와 같은 결과 값 출력

3 = name
name 내림차순 정렬 후 (가나다 역순), 같은 값은 category 오름차순 정렬

가격 순으로 오름차순 정렬 후 가격이 같으면 category 내림차순 정렬
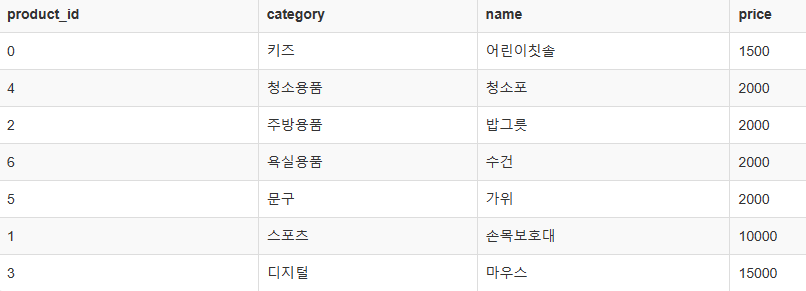

Price 오름차순 정렬 후 상위 3개 출력 = 가격이 낮은 3개 출력

집계 함수
SELECT뒤에 집계함수 사용. 여러 행으로부터 하나의 결과 값을 반환하는 함수
ex. 평균, 최대, 최소, 합

product_v2에 해당하는
- price 행의 합을 구하고 sum_price 컬럼명으로 결과 값 반환
- price 행의 평균 값을 구하고 avg_price 컬럼명으로 결과 값 반환

*AS 사용하기
컬럼명 수정 가능, 새로운 컬럼 추가 가능

name 이라는 컬럼명 name_v2로 변경,
1값을 가진 컬럼을 new_col 컬럼명으로 추가

COUNT 함수와 DISTINCT
count 함수
count(1) : 해당 테이블의 모든 행 갯수 출력 = count (*)
count(col): null값이 제외된 col 값 갯수 출력
distinct 함수
중복값 제외한 값을 출력

price 중 중복제외한 행의 갯수 출력


카테고리가 '용품'으로 끝나는 행의 갯수 출력

GROUP BY

salae_yn (현재 판매 가능 여부)가 yes 인 경우 집계함수 적용
GROUP BY: 1(카테고리)로 그룹화 적용
ORDER BY: sales_cnt의 내림차순으로 정렬, 같은 값이 있다면 1(카테고리)의 오름차순으로 정렬
-> sales_cnt가 2로 같기 때문에 가나다 순으로 정렬됨


GROUP BY 1,2: 1(카테고리)값과 2(sale_yn)기준으로 그룹화 하고, 그룹별 평균가 출력

HAVING
WHERE vs. HAVING
WHERE: 그룹화 하기 전에 필터링
HAVING: 그룹화 이후 필터링

price가 3000 이상인 행의 평균 가격을 1,2로 그룹화하여 출력하기


price 가 3000 이상인 행의 평균 가격을 1,2로 그룹화 하고,
그 중 sale_yn 값이 yes인 값만 출력하기
