JOIN이란 ?
두 개 이상의 테이블을 특정 key를 기준으로 결합하는 것
*테이블을 쪼개 놓는 이유
각 테이블을 효율적으로 관리 가능. 테이블끼리 JOIN을 통해 더 많은 활용 가능. 변경할 사항이 생길때 수정을 최소화할 수 있음.
INNER JOIN
두 테이블에서 값이 일치하는 행만 출력. 교집합을 구하면서 제외되는 행이 생기기때문에 실행시간이 줄어듦. 데이터 정확성이 높음.
SELECT 테이블.col, 테이블2.col
FROM 테이블1 INNER JOIN 테이블2 ON 테이블1.col = 테이블2.col
예제) clicks 테이블에 적재된 clicks수 중에 실제 구매로 이어진 클릭 찾아보기

ordered 가 1값인 컬럼추가.
clicks와 orders 테이블에서 user name, product_id, date가 같은 행 추출.
clicks와 product 테이블에서 proudct_id가 같으면 name 추출
LEFT JOIN
왼쪽 테이블의 모든 행을 가져오고 오른쪽 테이블에서 일치하는 행을 가져오고 일치하지 않으면 null값으로 처리

clicks 모든 행, ordered가 1값인 컬럼 추가, odr_index 출력
clicks 테이블과 orders 테이블 LEFT JOIN
clicks 테이블에서 user_name, proudct_id, date가 같은 값 모두 결합


위 테이블에서 상품 이름을 추가하려면 clicks와 porduct 테이블에서 product_id을 LIGHT JOIN하고 이름 출력



clicks와 orders 테이블 RIGHT JOIN
user_name, product_id, date가 같은 행들을 오른쪽 결합 후 orders테이블의 모든 컬럼과 clk_index 출력

odr_index가 0인 값 두 개 존재하는데 그 이유는 영희가 같은 상품에 대해서 같은날짜에 두 번 클릭했기 때문
-> LEFT, RIGHT JOIN은 행수가 늘어날 수도 있기 때문에 잘 확인해야 한다
CROSS JOIN
두 테이블 간 구할 수 있는 모든 조합, 무분별한 사용시 DB에 과부화 줄 수 있음. 클라우드 환경의 경우 비용 과도하게 청구될 수 있음


ex. 테이블 1의 상품을 구매하는 사람에게는 테이블2의 상품 중 하나 추천, 테이블2의 상품 구매하는 사람에게는 테이블1의 상품 중에서 추천 -> 상품간의 유사도를 구해야함

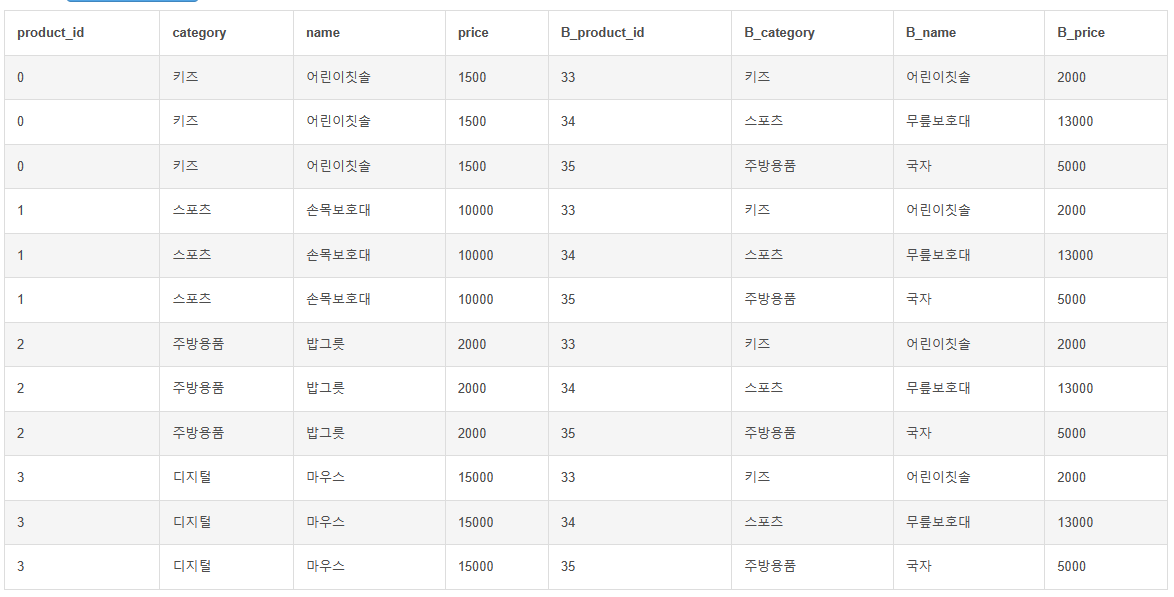
products 4행 * products_B 3행 = 12행 출력
category값과 B_category 값이 같으면 1점 아니면 0점
name 값과 B_name 같으면 1점 아니면
price 가격차이의 절댓값이 1000원 이내라면 1 아니면 0 등..
거리가 가까운 순으로 정렬하기
Alias (별칭)
FROM 테이블1 별칭1 (JOIN) 테이블2 별칭2
SELF JOIN
Alias 필수로 써주어야 중복되는 이름 구분 가능
UNION
중복되는 행 제거, SELECT 에서 필요한 테이블의 컬럼을 선택하고 병합. 열의 수와 데이터 타입 일치해야 병합가능
WITH (=CTE Common Table Expression)
임시 결과 집합을 생성하여 복잡한 쿼리를 쉽게 작성할 수 있또록 해줌
ex. WITH를 사용하여 고객별 상품수, 총 구매 금액, shipping id 수 구하기

ord_cnt=> customer과 orders 테이블에서 customer_id가 같은 값을 가지는 행을 INNER JOIN,
order수가 유저별로 몇 개인지 cont distinct, 총 주문금 sum(amout) 출력
ship_cnt => customer과 shipping 테이블에서 cusomer_id와 custoemr값이 같으면 status가 pending인 customer_id와 중복제거한 shipp_id 출력
COALESCE: ship_cnt 가 null이면 0으로 처리 후 ord_cnt, ship_cnt 출력

customer_id 마다 주문수, 총 주문금액, 배송중인 아이템 수를 출력한 결과
Subquery
다른 쿼리 내부에 포함된 쿼리. 복잡한 쿼리를 사용하여 데이터를 추출하거나, 테이블 관계를 확인하는 등에 사용됨. 지나친 사용은 리소스를 지나치게 많이 사용할 수 있기 때문에 성능 최적화에 신경써야함
ex1. SELECT에서 서브쿼리 사용하기 - 유저별 평균 구매 가격과,전체 평균 구매 가격을 비교하기

orders 테이블, products 테이블에서 product_id가 같은 행 INNER JOIN하고, user_name으로 묶기,
평균 구매 금액을 기준으로 내림차순정렬 user_name, price의 평균값 출력


orders 테이블, products 테이블에서 product_id가 같은 행의 price의 평균값 구하기

서브쿼리 적용 예시

전체 상품의 평균 금액을 구한 값을 total_avg_price로 정하고, user_name, 구매한 물건의 평균 값과 함께 출력

ex2. FROM 에서 서브쿼리 사용하기 - 스포츠/ 주방용품 매니저들의 클릭 이력 가져오기
JOIN해야 하는 테이블이 클수록 필터링을 미리 해놓으면 성능에 부담이 적다.

managers 테이블에서 '스포츠'와 '주방용품'을 관리하는 name 추출


추출한 이름 컬럼을 a로 지정, clicks 테이블과 name = user_name인 행들 INNER JOIN 후 해당 컬럼 모두 출력

'DA' 카테고리의 다른 글
| 데이퍼 파이프라인이란 | 데이터 파이프 라인 만들 때 고려할 점 (0) | 2024.01.23 |
|---|---|
| 데이터레이크|데이터웨어하우스|Airflow|ETL,ELT (2) | 2024.01.22 |
| [TIL] SQL - DDL과 DML (0) | 2023.12.05 |
| [TIL]SQL ORDER BY| GROUP BY |DESC, ASC | HAVING | COUNT (0) | 2023.12.04 |
| [TIL] SQL 비교 연산자 <> | AND, OR | IN, NOT IN| LIKE |BETWEEN (0) | 2023.12.04 |